Qwen2: Scene Description Model
To provide clear and context-rich visual descriptions, we evaluated several Visual Language Models (VLMs). Qwen2 consistently outperformed Paligemma in both qualitative and quantitative metrics.
Overall Evaluation Summary
We scored models on three custom designed metrics across 30 real-world urban scenes:
- Navigation Safety: Identifying obstacles, hazards, and safe paths
- Spatial Orientation: Helping users build a mental map
- Environmental Awareness: Providing relevant context (e.g., weather, time, ambiance)
Overall Evaluation Scores
| Model | Navigation Safety | Spatial Orientation | Environmental Awareness | Overall |
|---|---|---|---|---|
| Paligemma | 3.0 | 2.1 | 2.2 | 2.4 |
| Qwen2 | 3.9 | 3.8 | 3.9 | 3.9 |
| Gap | +0.9 | +1.7 | +1.7 | +1.4 |
Why Qwen2?
- 67% better performance across all evaluation metrics
- 4–6x more detailed descriptions (avg. 65–70 words vs. 11–12)
- Higher accuracy in describing surroundings, layout, and spatial cues
Scene Example: Which Model Describes Better?
We prompted both models with the same question for the picture shown:

Paligemma’s Response
“The image is a video of a crosswalk with a person and a car in the middle of the road.”
Qwen2’s Response
“The image shows a city street scene during the day time. There are several people crossing the street at the pedestrian crossing marked with yellow line. The street is relatively wide and has a few cars parked along the side. There are trees with blooming flowers likely cherry blossoms…”
Scoring Comparison
| Metric | Paligemma | Explanation | Qwen2 | Explanation |
|---|---|---|---|---|
| Navigation Safety | 2.5 | - Mentions person & car - No crosswalk or signals - Vague on safety context |
3.0 | - Notes pedestrian crossing - Mentions people walking - No traffic signal info |
| Spatial Orientation | 1.0 | - Only says “crosswalk” - No layout or direction - No reference points |
4.0 | - Describes street & parked cars - Mentions crosswalk & layout - Good scene structure |
| Environmental Awareness | 1.0 | - No weather/time info - No surroundings - Just car & person |
3.8 | - Mentions trees & cherry blossoms - Notes daytime setting - Adds calm ambiance |
| Overall | 1.5 | - Object-level only - Missing context - Not helpful for navigation |
3.6 | - Balanced description - Good spatial & environmental cues - Supports user needs |
Metrics-Based Caption Evaluation
We also evaluated the generated descriptions using NLP similarity metrics between model captions and human-written ones, Qwen2 also has higher scores across:
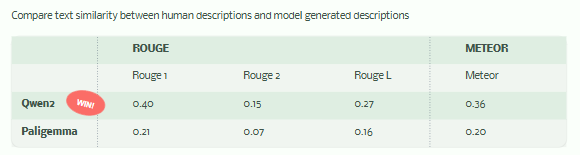
Qwen2 outperforms in ROUGE and METEOR, showing more overlap and fluency with human references